Industrie 4.0 verandert de manier waarop we produceren, tot zover ouwe koek mag ik stellen. Concepten, zoals voorspellend onderhoud, vraagvoorspelling en digitale tweelingen, verminderen niet alleen de downtime van machines en kwaliteitsuitval, maar kunnen ook helpen de productie-efficiëntie te optimaliseren. De vruchten van deze inspanningen moeten minstens tastbaar zijn. PricewaterhouseCoopers verwacht dat Industrie 4.0-inspanningen een kleine 400 miljard dollar aan efficiëntiewinst zullen opleveren.
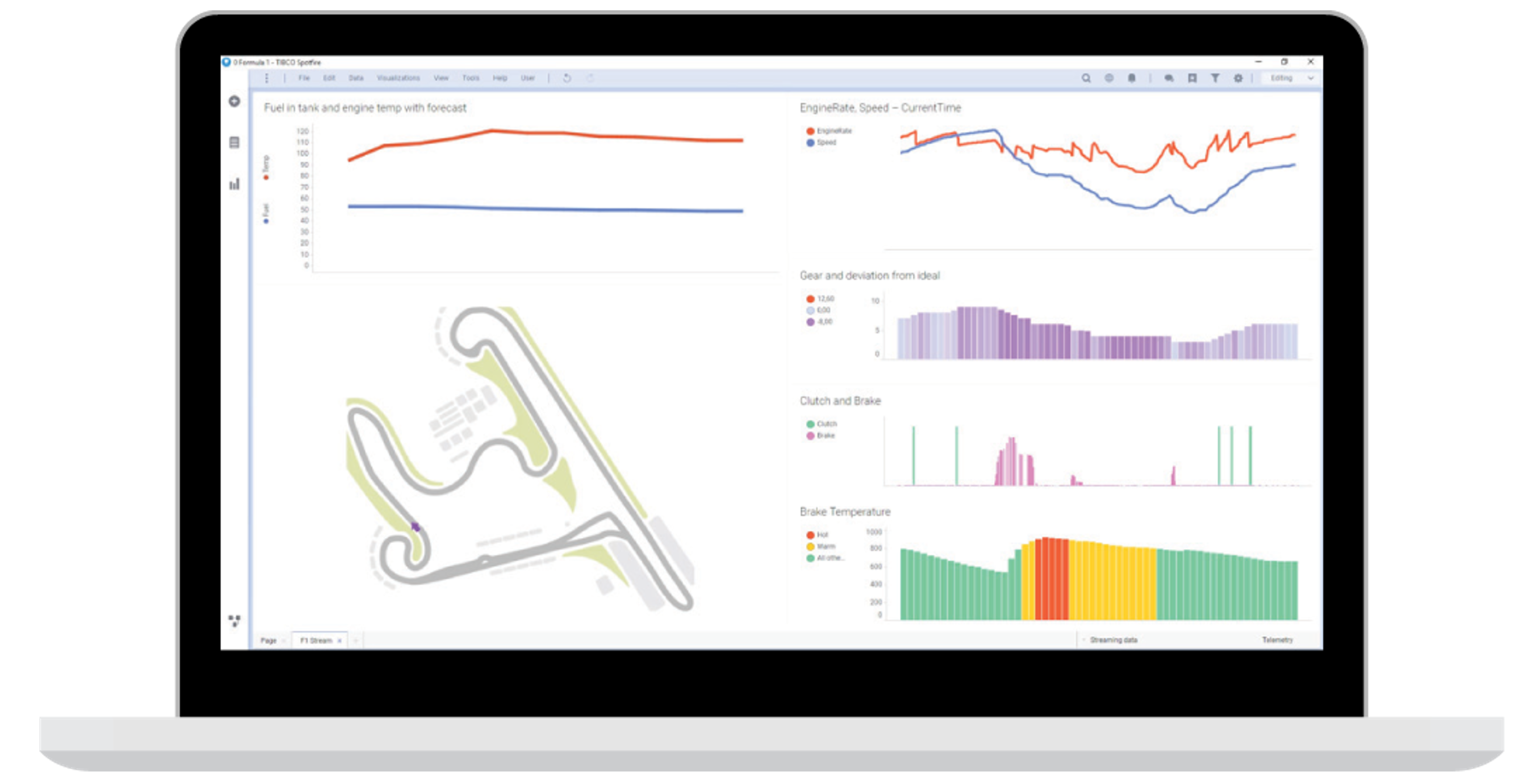
Bij deze evolutie naar Industrie 4.0 komen echter heel wat geavanceerde technologieën kijken. Het landschap is nieuw en uitdagend. Als gevolg daarvan kunnen zelfs de grootste Fortune 500-bedrijven de taak om standaardarchitecturen te ontwikkelen voor het verzamelen en verwerken van stromen productiegegevens ontmoedigend vinden. Dus waarom zou een kmo daar dan tijd en geld in steken?
Er bestaat geen uniforme strategie voor de ontwikkeling van een Industrie 4.0-architectuur. Er moet kritisch belang worden gehecht aan het classificeren van gegevens en het ontwerpen van systemen om de verschillende soorten beschikbare data te verwerken. Industrie 4.0 ontsluit een grote hoeveelheid gegevens en die zijn niet allemaal gelijk. Bij de meeste kmo’s is de vrees er dat eenmaal je begint, de doos van Pandora wordt geopend.
Om dit te begrijpen, is het cruciaal te beseffen dat de meeste industriële gegevensstreaming op tijd gebaseerd is. Een vacuümoven kan bijvoorbeeld elke seconde een vacuümgegevenspunt genereren, terwijl een productiesysteem (MES) elke vijf minuten een gegevenspunt over de voltooiing van een route kan genereren. Hoewel de inhoud en de vorm van de twee datapunten verschillen, zijn het allebei stromen.
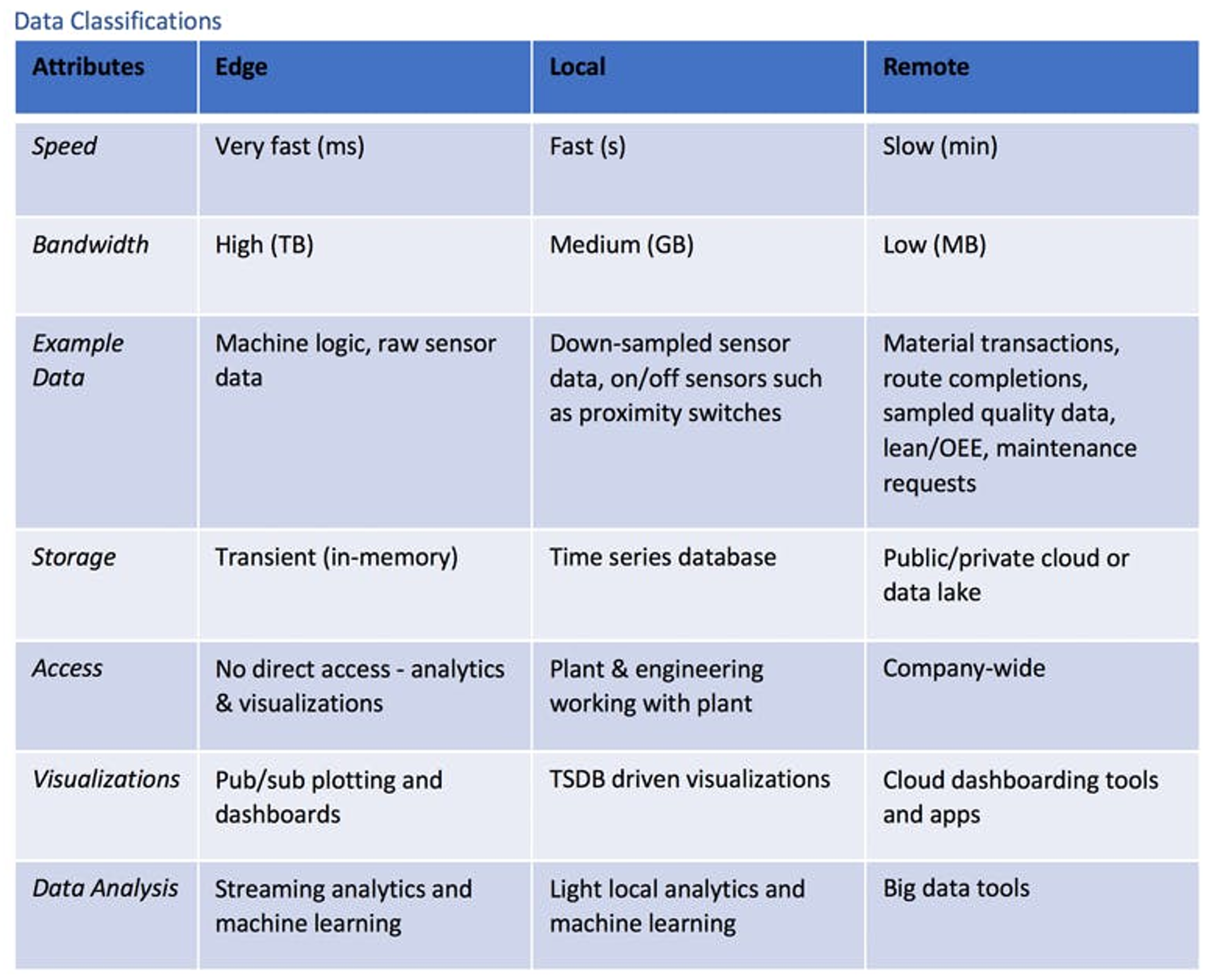
Gegevensstromen kunnen worden gedefinieerd aan de hand van kenmerken, zoals bandbreedte en gebruik. Als deze eigenschappen eenmaal zijn gegroepeerd op overeenkomsten, komen de volgende logische drie klassen van industriële gegevens aan het oppervlakte : edge, lokaal (on premise) en remote (cloud/lake).
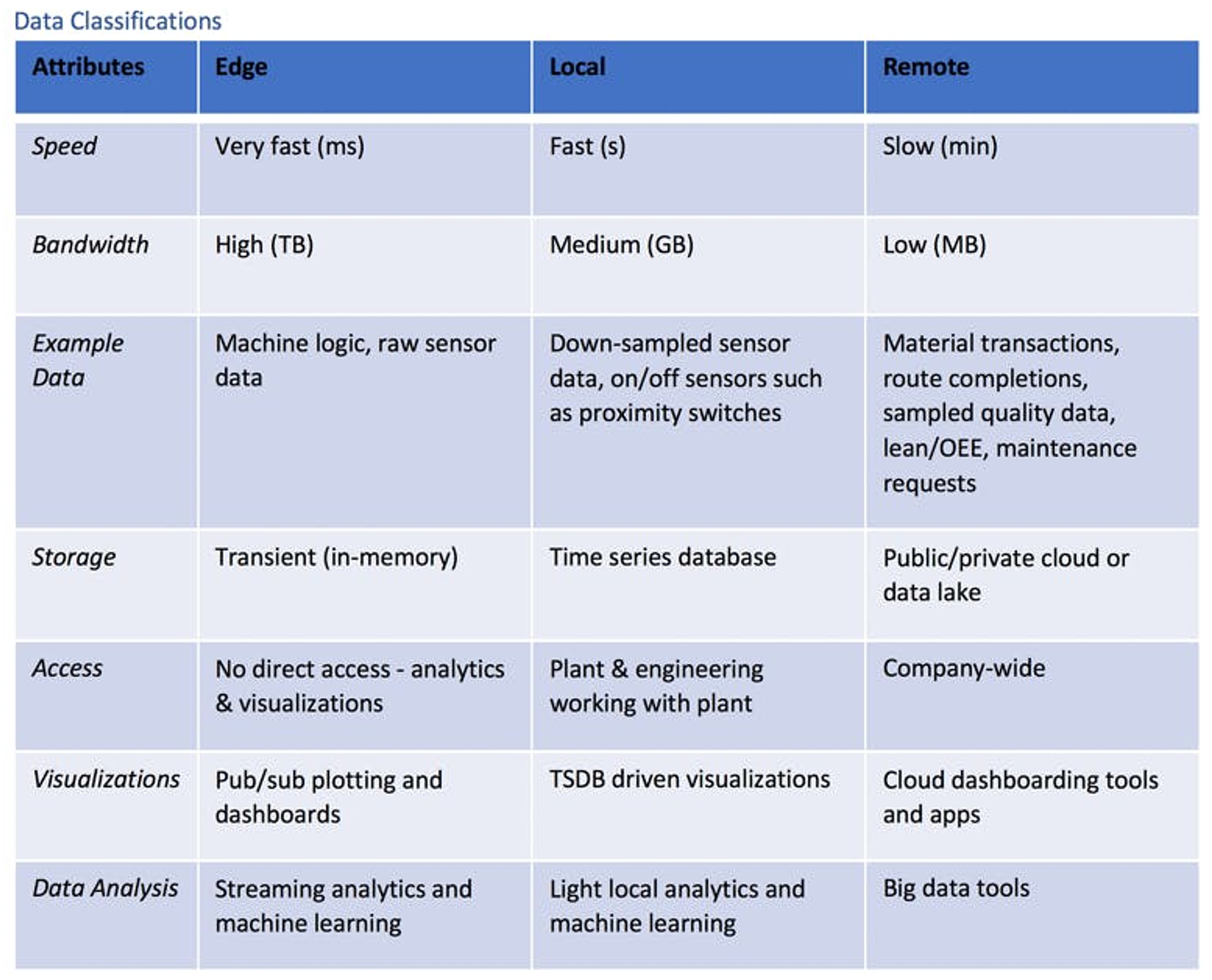
Illustratie: Industry 4.0 datastreamingmethodes edge, on premise en remote.
Randgegevens zijn momentdata: ze worden samen met de inzichten weggegooid. Combineren is de kunst
Randgegevens zijn snel, realtime en van voorbijgaande aard. De eerder genoemde vacuümoven kan zeer snel vacuüm- en temperatuurgegevens genereren. Vóór Industrie 4.0 werden de gegenereerde gegevens gedownsampled en dus grotendeels weggegooid. Gegevensstromen die geen technische resultaten bevatten, zoals machinelogica, zouden volledig verloren zijn gegaan.
Het probleem met het weggooien van deze gegevens is natuurlijk het verlies van veel waardevolle inzichten. Stel bijvoorbeeld dat de vacuümoven begint te haperen als de vacuümpomp problemen heeft. Als de gegevens met hoge bandbreedte en de machinelogica waren opgeslagen, zou een patroon of handtekening zijn geïdentificeerd om deze toestand te diagnosticeren en kan er in real-time een onderhoudsverzoek word ingediend.
Bovendien kan de verwerking van combinaties van sensorstromen of sensorfusie zeer waardevolle transactie-informatie opleveren. Stel dat de onderdelen, die de oven ingaan, voorzien zijn van zichtbare barcodes. Door een barcodescanner, de besturingslogica en de operationele kenmerken van de oven te combineren, hebben operators volledig inzicht in de status van dat onderdeel in het proces. Door deze context te combineren met proceskenmerken en er trends uit te halen, kunnen realtime, voorspellende modellen worden gebouwd om zowel de machine-efficiëntie als de productkwaliteit te optimaliseren.
De uitdaging bij edge data is natuurlijk de bandbreedte. Het opslaan van de tienduizenden of zelfs honderdduizenden sensor- en logicastromen in een fabriek is duur en onpraktisch. De enige manier om de beschikbare attributen en inzichten te ontsluiten, is de plaatsing van highspeed analytics bij de bron van de gegevensverzameling zelf.
Complexe gebeurtenissen verwerken met streamingsensordata
Een nuttig edge analytics-platform combineert een realtime streaming analyticslaag met data conditioning-tools, realtime visualisaties en geavanceerde machine learning-mogelijkheden. Streaming analytics-engines kunnen doorgaans geen traditionele programmeertalen gebruiken vanwege het eventdriven karakter van streaming sensordata. Elk platform heeft zijn eigen unieke oplossing om streaming analytics te ontwikkelen. Deze engines bestaan in vele vormen, maar zijn over het algemeen op complexe gebeurtenissenverwerking (CEP) of regels gebaseerd.
Omdat het beheer van honderden of duizenden edges afzonderlijk onpraktisch is, wordt edge analytics best aan een gecentraliseerd beheer gekoppeld voor gedistribueerde orkestratie en het op afstand schrijven van analytics. Informatie uit streaming analytics, die bestaat als een classificatie op een hoger niveau (lokaal of op afstand), kan vervolgens naar elk ander systeem of database worden verzonden.
Valkuilen, waarvoor men moet oppassen bij edge-platforms, zijn een gebrek aan capaciteit, moeilijk te gebruiken configuraties en eigen geprogrammeerde analytics, die niet uit het ecosysteem van een standaard provider kunnen worden gehaald. Afwegingen tussen verschillende streaming analytics-implementaties zijn eveneens mogelijk. CEP-engines zijn flexibeler en kunnen complexere processen modelleren, maar vereisen doorgaans meer werk in de configuraties vooraf. Op regels gebaseerde engines beperken zich op hun beurt meestal tot eenvoudige waarschuwingen en voorwaardelijke monitoring, maar zijn veel sneller en makkelijker in gebruik te nemen.
Illustratie : Een realtime machinegestuurd statistisch procescontrolplot, aangestuurd door sensorfusie CEP-gegevens.
Lokale gegevens zijn minder tijdelijk en basis voor scada, dashboards en debuggen
Lokale gegevens zijn al tientallen jaren de traditionele focus van toezichthoudende controle en gegevensverwerving (SCADA). In tegenstelling tot randgegevens zijn lokale gegevens niet van voorbijgaande aard. Maar om de capaciteit aan bandbreedte en opslag te beperken, worden lokale gegevens systematisch gedownsampled. Ze worden doorgaans ook opgeslagen op een locatie dicht bij de edgedata. Deze gegevens zijn nuttig om te bewaren voor dashboards, het debuggen van processen en een procescontext die niet realtime kritisch is. In de vacuümoven worden bijvoorbeeld de gedownsamplede temperatuur- en drukgegevens geclassificeerd als lokale gegevens en bewaard om problemen op te lossen.
Veel randplatforms bevatten hun eigen lokale tijdreeksdatabases. Tijdreeksdatabases verschillen van relationele databases, doordat ze geoptimaliseerd zijn voor het opslaan en opvragen van niet-periodieke tijdreeksgegevens. Een tijdstempel geeft doorgaans het verband tussen verschillende gegevensreeksen aan. Naast het bewaren van kritieke gegevens kan deze database worden gebruikt voor het opslaan en aansturen van dashboards of van lokale analyses en waarschuwingen. In veel populaire databases kan ook een bewaarbeleid worden ingesteld, zodat de gegevens slechts gedurende een bepaalde periode opgeslagen blijven.
Gegevens op afstand (cloud en datalakes): minder dan een 1000e van de edge bandbreedte en ruimere interpretaties beschikbaar
Het belangrijkste verschil met gegevens op afstand is niet alleen de frequentie, maar ook de aard van de gegevens. Gegevens in de cloud of zelfs in een datalake van een organisatie opslaan, is vaak erg duur en vereist veel bandbreedte. Daarom moeten data in een systeem op afstand worden beperkt tot gegevens, waar grote aantallen geografisch verspreide gebruikers toegang tot moeten hebben. Als vuistregel geldt dat de bandbreedte van die data minder dan een duizendste van de aan de rand beschikbare gegevens moet bedragen.
Gegevens in cloud of datalake zijn daarom over het algemeen transactionele gegevens over onderdelen en processen. Processtatus, afgelegde routes en kwaliteitskenmerken zijn voorbeelden van gegeven,s die nuttig zijn in een centrale datalake of een cloud.
Veel van de sensorfusie-informatie, die via een streaming analyseplatform uit ruwe data aan de rand wordt gehaald, behoort uiteindelijk tot de klasse van gegevens op afstand/cloud. Om terug te komen op het voorbeeld van de vacuümoven: denk aan de mogelijkheid om de exacte staat van elk onderdeel of proces vast te leggen. Een streaming analytics-engine kan de informatie van deze toestanden opnieuw verpakken en vervolgens MES- en materiaaltransacties automatiseren, evenals de bijbehorende kwaliteitskenmerken. Deze transacties en kwaliteitskenmerken kunnen nuttig zijn voor andere fabrieken en de leiding van de toeleveringsketen. Daarnaast kunnen ze dienen voor classificaties van gegevensgebruik op afstand.
Wat hebben we nu eigenlijk geleerd?
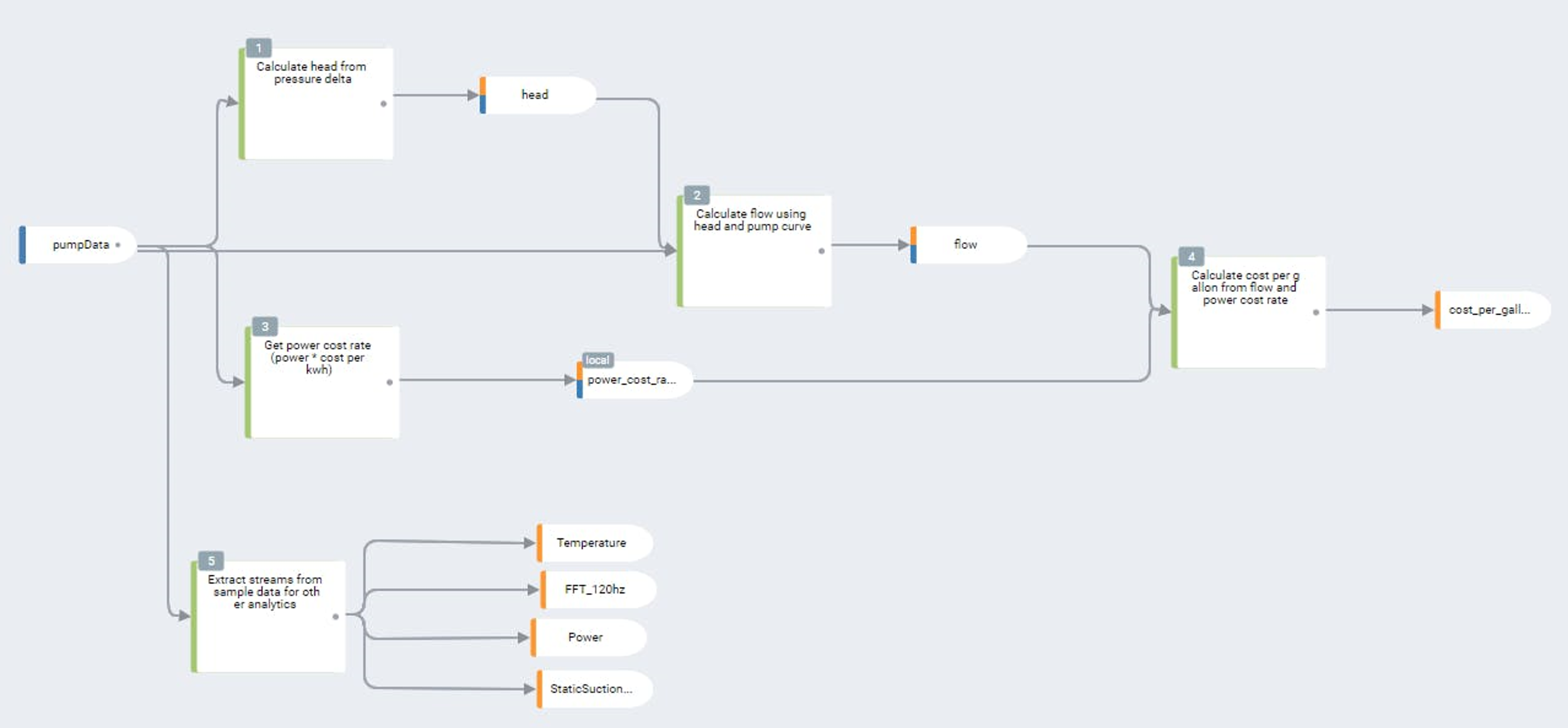
Een effectieve Industrie 4.0-architectuur moet zich richten op drie soorten gegevens: edge, lokaal en remote. Ontwerpen voor één type gegevens houdt een risico in op het verlies van kritieke procesinformatie en waardevolle inzichten. Kortom, inzoomen enkel op edge, lokaal of remote is altijd kiezen en dus verliezen.