L'Industrie 4.0 est en train de changer la façon dont nous fabriquons, ce qui n'a plus rien de nouveau en soi, si je puis me permettre. Des concepts tels que la maintenance prédictive, la prévision de la demande et les jumeaux numériques permettent non seulement de réduire les temps d'arrêt des machines et les pertes de qualité, mais aussi d'optimiser l'efficacité de la production. Les fruits de ces efforts doivent tout au moins être tangibles. Price Waterhouse Cooper s'attend notamment à ce que les efforts fournis dans le cadre de l'Industrie 4.0 génèrent un peu moins de 400 milliards de dollars en gains d'efficacité.
Cette évolution vers l'Industrie 4.0 implique toutefois le recours à de nombreuses technologies de pointe. Le paysage industriel global est à la fois nouveau et semé d'embûches. Par conséquent, même les plus grandes entreprises du classement Fortune 500 peuvent se sentir dépassées par la tâche consistant à développer des architectures normalisées permettant de collecter et traiter des flux de données de fabrication. Pourquoi donc une PME devrait-elle y investir du temps et de l'argent ?
Il n'existe pas de stratégie uniforme pour développer une architecture conforme aux exigences de l'Industrie 4.0. Il est essentiel d'accorder une importance capitale à la classification des données et à la conception de systèmes permettant de traiter les différents types de données disponibles. L'Industrie 4.0 permet de disposer d'une grande quantité de données, mais celles-ci ne sont pas toutes égales. Dans la plupart des PME, on craint que la boîte de Pandore s'ouvre dès le lancement de tous ces nouveaux projets.
Pour comprendre cela, il faut d'abord savoir que la plupart des données industrielles sont basées sur le temps et générées en flux continu. Un four sous vide, par exemple, peut générer un point de données sur le vide toutes les secondes, tandis qu'un logiciel de pilotage de la production (MES) peut générer un point de données sur le déroulement du projet toutes les cinq minutes. Bien que le contenu et la forme de ces deux points de données diffèrent, ils constituent tous deux des flux.
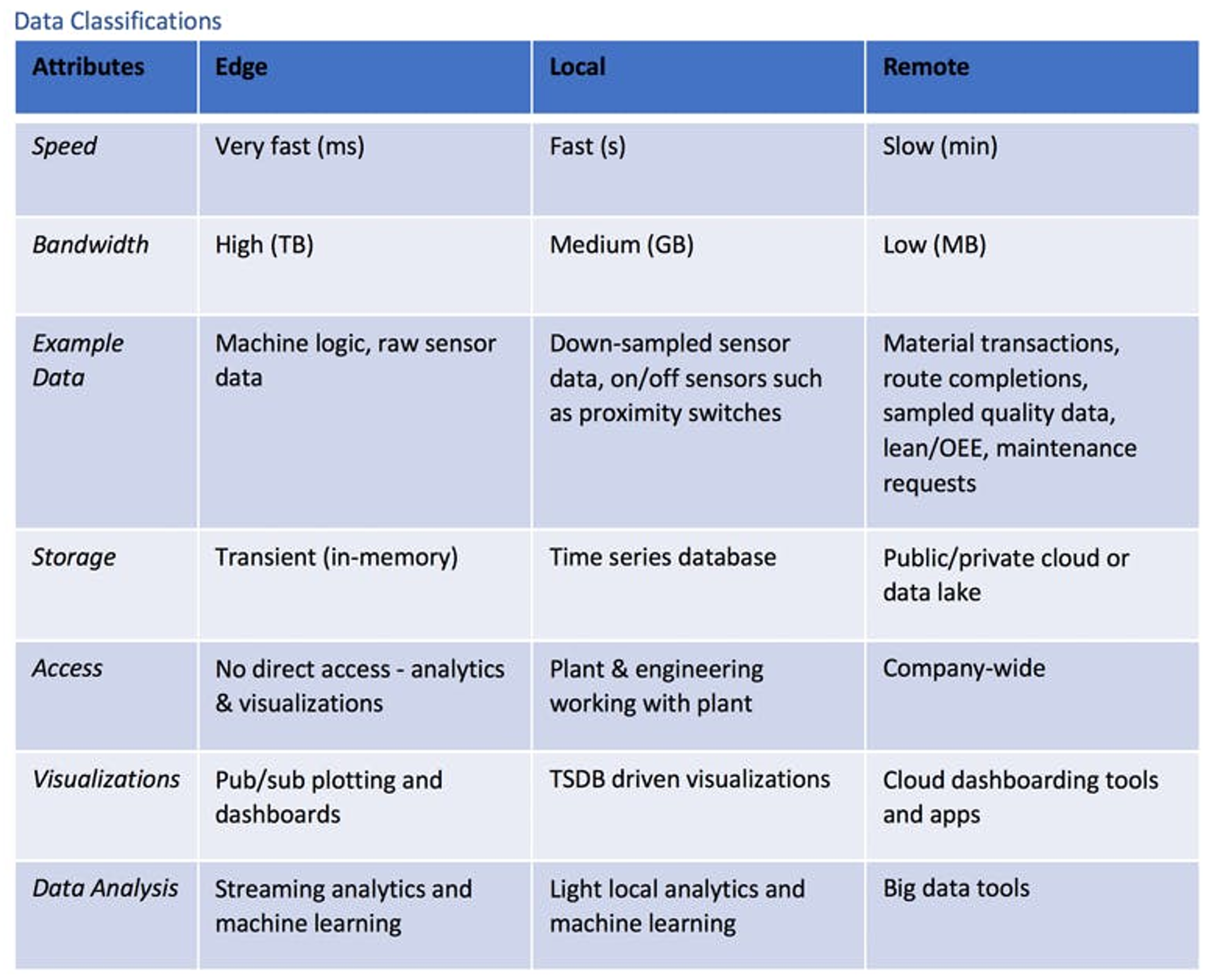
Les flux de données peuvent être définis par des caractéristiques telles que la bande passante et l'utilisation. Une fois ces caractéristiques regroupées par similitude, on obtient les trois classes logiques de données industrielles suivantes : Edge, Local (on premise) et Remote (cloud/lake).
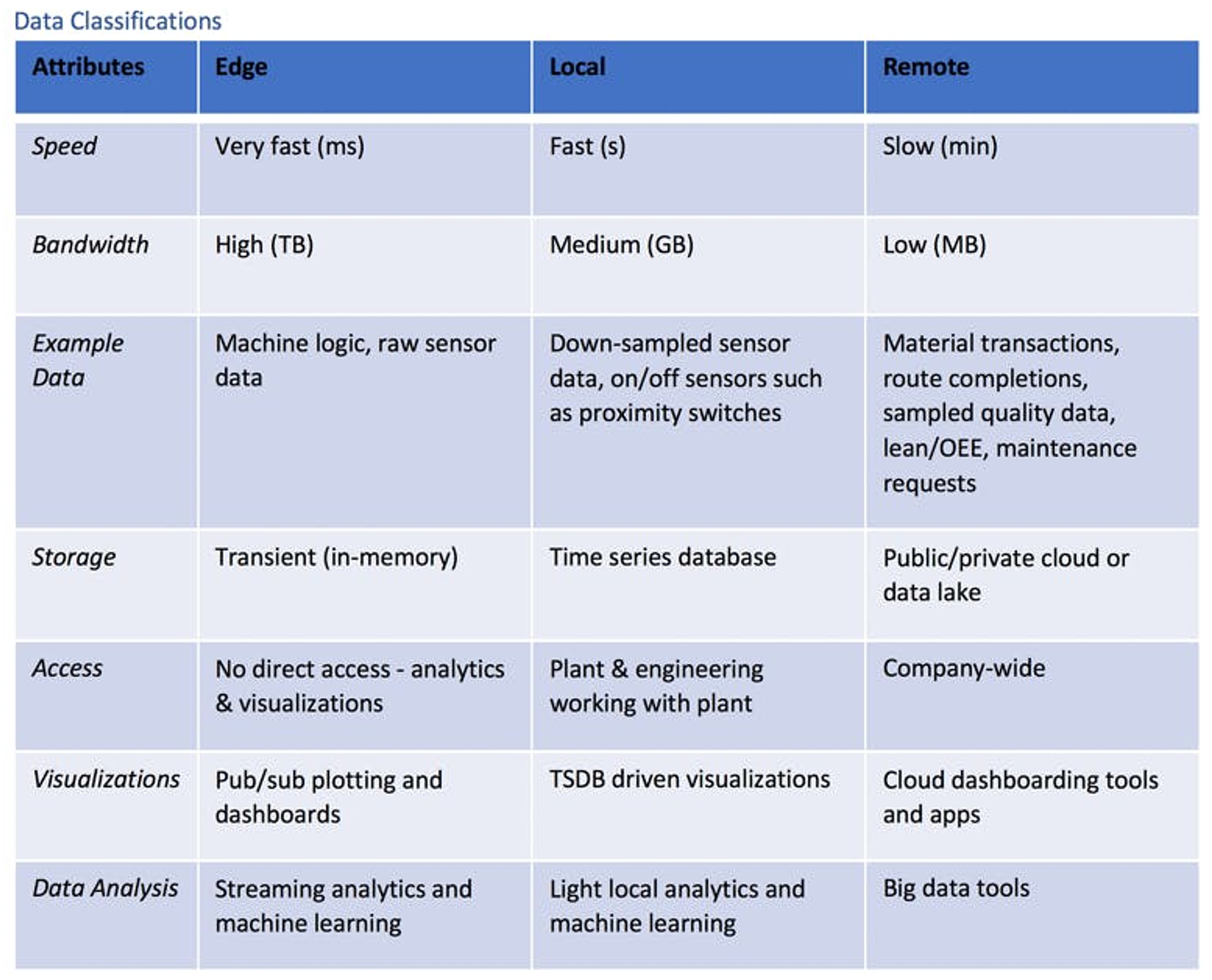 Illustration : Méthodes de streaming des données de l'Industrie 4.0 : Edge, Local (on premise) et Remote
Illustration : Méthodes de streaming des données de l'Industrie 4.0 : Edge, Local (on premise) et Remote
Les données périphériques sont des données momentanées, qui sont éliminées en même temps que les informations – l'idéal est de les combiner
Les données périphériques sont rapides, en temps réel et de nature transitoire. Le four sous vide susmentionné est capable de générer des données relatives au vide et à la température très rapidement. Avant l'Industrie 4.0, les données générées étaient sous-échantillonnées et donc en grande partie éliminées. Les flux de données qui ne contenaient pas de résultats techniques, comme ceux provenant des circuits logiques des équipements, étaient ainsi complètement perdus.
Le problème de l'élimination de ces données, bien sûr, est la perte de nombreuses informations potentiellement précieuses. Imaginons, par exemple, que le four sous vide commence à faiblir lorsque la pompe à vide rencontre des problèmes. Si les données nécessitant une large bande passante et celles des circuits logiques des équipements avaient été stockées, il aurait été possible d'identifier un modèle ou une signature permettant de diagnostiquer cet état et de soumettre une demande de maintenance en temps réel.
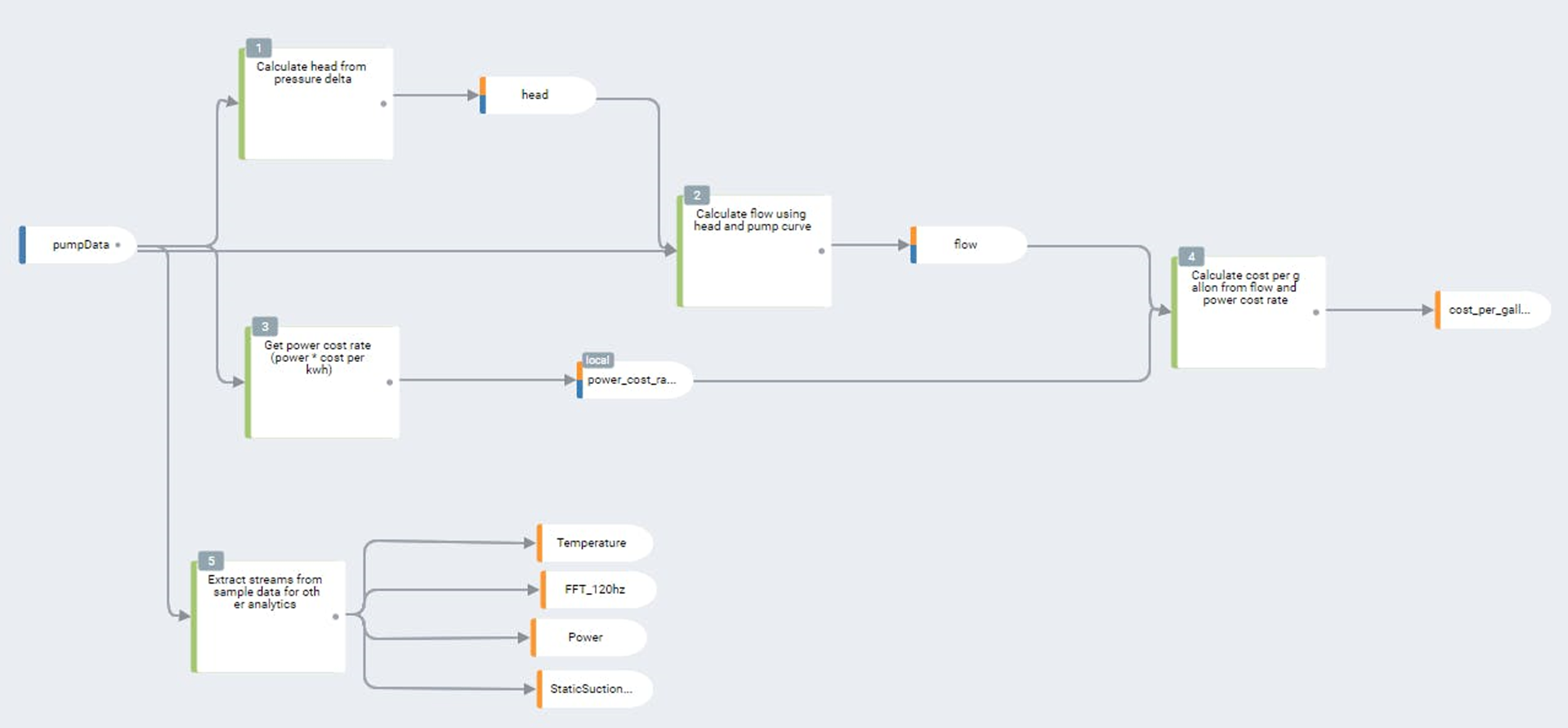
En outre, le traitement de combinaisons de flux de capteurs (fusion de capteurs) peut fournir des informations transactionnelles très précieuses. Supposons que les pièces introduites dans le four soient munies de codes-barres visibles. En combinant un lecteur de codes-barres, des circuits logiques de commande et les caractéristiques opérationnelles du four, les opérateurs disposent d'un aperçu complet de l'état de cette pièce dans le processus. En combinant ce contexte avec les caractéristiques du processus et en en extrayant des tendances, des modèles prédictifs en temps réel peuvent être élaborés en vue d'optimiser à la fois l'efficacité des machines et la qualité des produits.
Le défi que représentent les données périphériques est, bien entendu, la bande passante. Le stockage des dizaines, voire des centaines de milliers de flux de capteurs et de circuits logiques dans une usine est coûteux et peu pratique. La seule façon de mettre à profit les attributs et les informations disponibles est de placer l'analyse de données à haut débit à la source même de la génération des données.
Complexe gebeurtenissen verwerken met streamingsensordata
Une plateforme d'analyse de données périphériques efficace combine une couche d'analyse de flux de données en temps réel avec des outils de conditionnement des données, des visualisations en temps réel et des fonctionnalités d'apprentissage automatique de pointe. Les moteurs d'analyse de données en continu ne peuvent généralement pas utiliser les langages de programmation traditionnels en raison du caractère événementiel des données de capteurs en continu. Chaque plateforme possède sa propre solution unique pour développer l'analyse de données en continu. Ces moteurs se présentent sous de nombreuses formes, mais sont généralement basés sur le traitement des événements complexes (en anglais : complex event processing ou CEP) ou sur des règles.
Dans la mesure où la gestion individuelle de centaines ou de milliers de périphéries peut s'avérer peu pratique, l'analyse des données périphériques doit être combinée à une gestion centralisée pour une orchestration distribuée et une écriture à distance des données. Les informations provenant de l'analyse de données en continu, qui existent en tant que classification de niveau supérieur (local ou distant), peuvent ensuite être transmises à tout autre système ou toute autre base de données.
Les écueils dont il faut se méfier avec les plateformes edge sont le manque de capacité, les configurations difficiles à utiliser et les analyses de données programmées de manière spécifique et qui sont impossibles à extraire de l'écosystème d'un fournisseur standard. Il peut également y avoir des compromis à faire entre les différentes mises en œuvre des systèmes d'analyse de données en continu. Les moteurs CEP sont plus flexibles et sont capables de modéliser des processus plus complexes, mais ils nécessitent généralement plus de travail au niveau des configurations au départ. Les moteurs basés sur des règles se limitent généralement à de simples alertes et à une surveillance conditionnelle, mais ils sont beaucoup plus rapides et faciles à déployer.
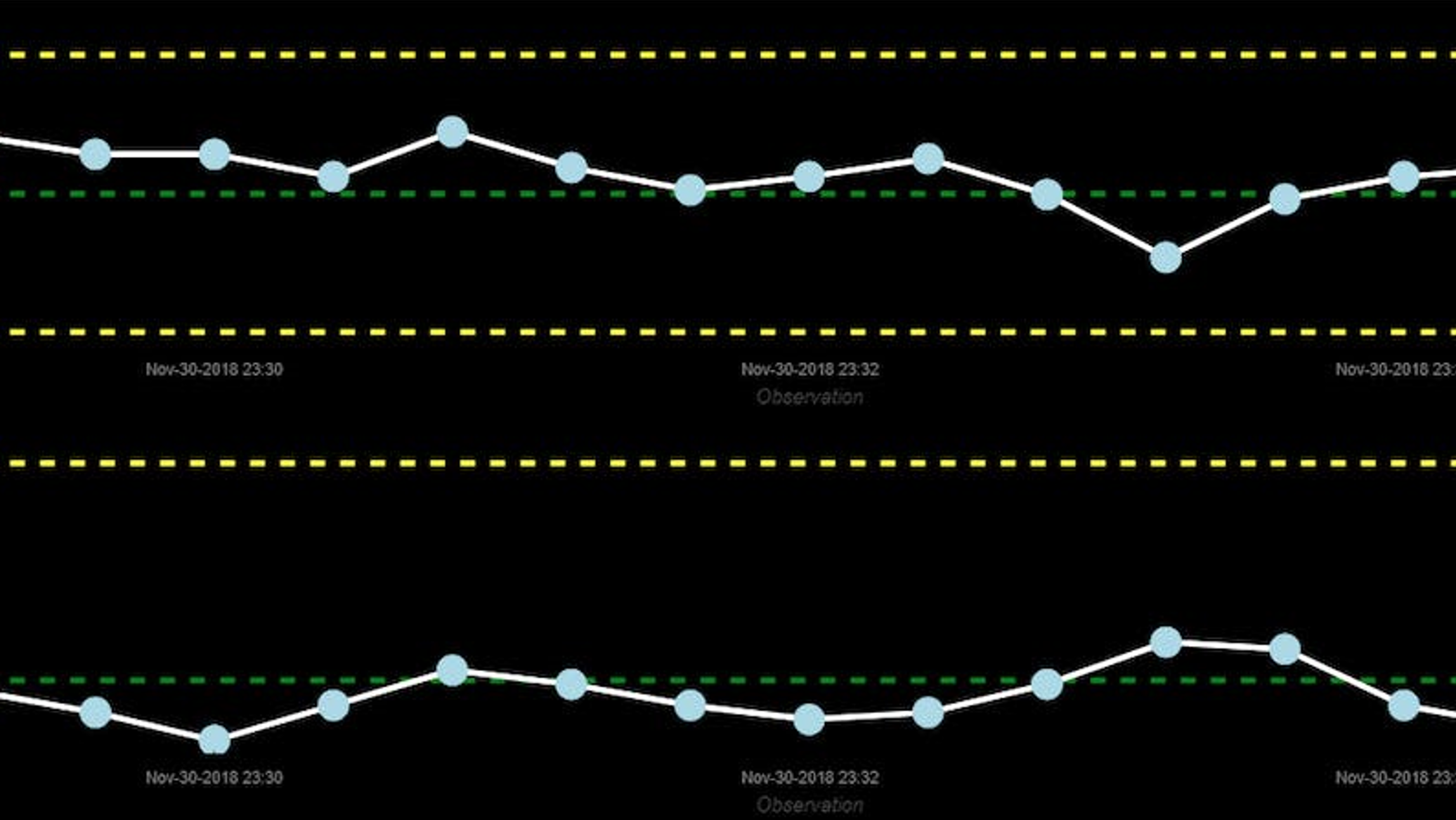
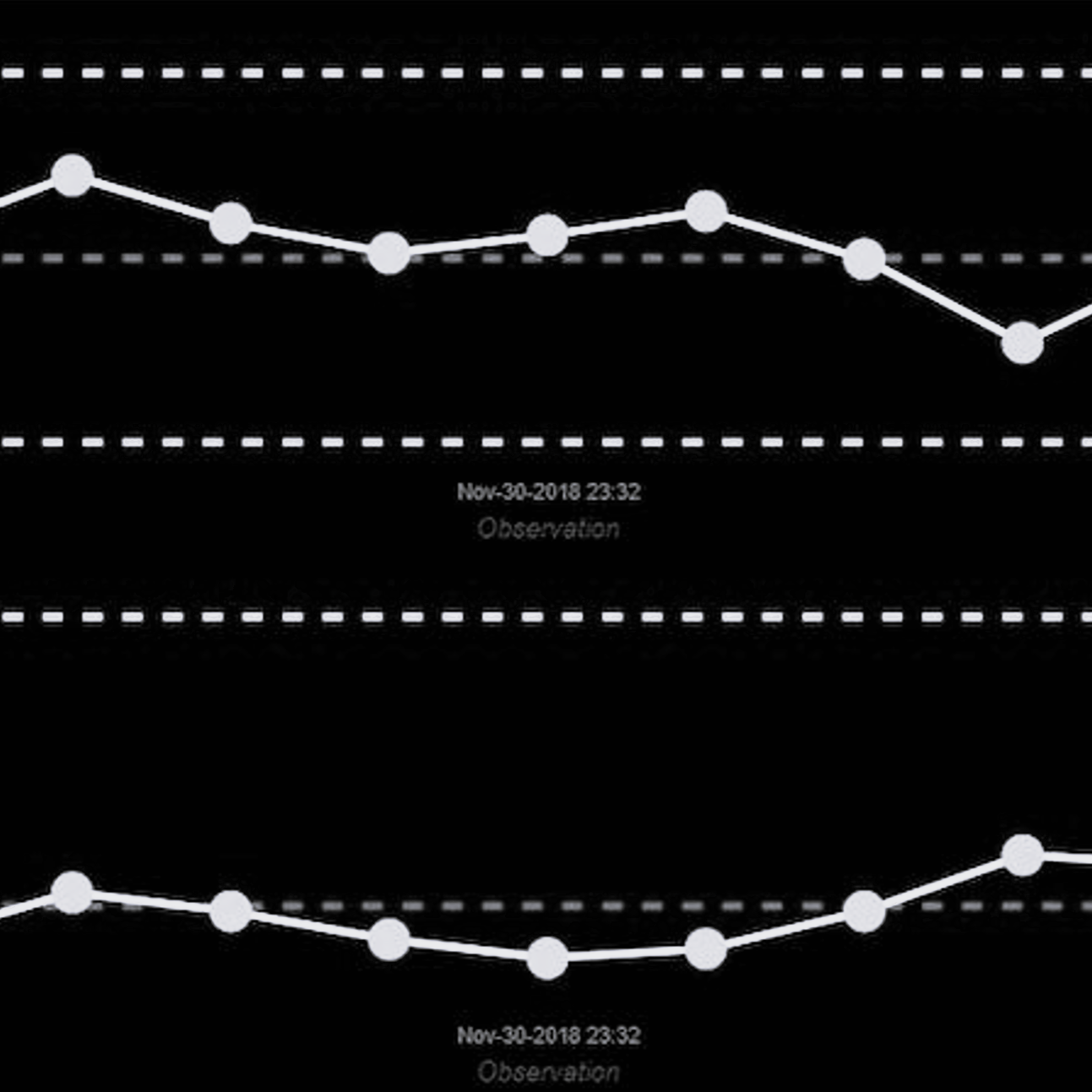
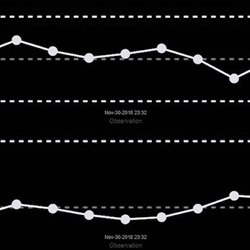
Illustration : Un graphique de contrôle de processus statistique en temps réel piloté par la machine et basé sur des données CEP de fusion de capteurs.
Les données locales sont moins temporaires, bien qu'elles soient locales, et servent de base pour les applications SCADA, les tableaux de bord et le débogage
Depuis des décennies, les données locales sont au centre des préoccupations des systèmes de contrôle et d'acquisition de données (SCADA). Contrairement aux données périphériques, les données locales ne sont pas de nature transitoire. Mais pour réduire les besoins en bande passante et en stockage, les données locales sont systématiquement sous-échantillonnées. Elles sont aussi généralement stockées à proximité des données périphériques. Ces données sont utiles à conserver pour les tableaux de bord, le débogage des processus et le contexte des processus qui n'est pas critique en temps réel. Dans l'exemple du four sous vide, les données de température et de pression sous-échantillonnées sont classées parmi les données locales et conservées à des fins de dépannage.
De nombreuses plateformes edge proposent leurs propres bases de données locales de séries chronologiques. Les bases de données de séries chronologiques se distinguent des bases de données relationnelles par le fait qu'elles sont optimisées pour le stockage et la récupération de données de séries chronologiques apériodiques. Un horodatage indique généralement la relation entre différentes séries de données. Outre le stockage de données critiques, cette base de données peut être utilisée pour stocker et piloter des tableaux de bord, ou pour piloter des analyses et des alertes locales. Dans de nombreuses bases de données très répandues, il est également possible de définir des politiques de rétention permettant de ne conserver les données que pendant un certain laps de temps.
Données à distance (cloud et lacs de données) : moins d'un millième de la bande passante nécessaire en périphérie et interprétations plus complètes disponibles
La principale différence avec les données à distance ne réside pas seulement dans la fréquence, mais aussi dans la nature même des données. Le stockage des données dans le cloud, ou même dans le lac de données d'une entreprise, est souvent très coûteux et nécessite une bande passante considérable. Par conséquent, les données d'un système distant doivent se limiter aux données auxquelles un grand nombre d'utilisateurs géographiquement dispersés doivent avoir accès. En règle générale, la bande passante nécessaire pour ces données est inférieure à un millième de la bande passante nécessaire pour les données disponibles au niveau de la périphérie.
Les données stockées dans le cloud ou les lacs de données sont donc généralement des données transactionnelles concernant des composants et des processus. L'état des processus, les itinéraires parcourus et les caractéristiques de qualité sont des exemples de données utiles dans un lac de données central ou le cloud.
Une grande partie des informations de fusion de capteurs obtenues à partir de données brutes au niveau de la périphérie via une plateforme d'analyse de données en continu appartient finalement à la catégorie des données à distance/dans le cloud. Pour revenir à notre exemple du four sous vide, pensez à la possibilité de connaître l'état exact de chaque composant ou processus. Un moteur d'analyse de données en continu pourrait reconditionner les informations de ces états, puis automatiser les transactions MES et matérielles, ainsi que les attributs de qualité associés. Ces transactions et caractéristiques de qualité pourraient être utiles à d'autres usines et aux responsables de la chaîne d'approvisionnement et seraient parfaitement adaptées à la classification de l'utilisation des données à distance.
Qu'avons-nous appris en réalité ?
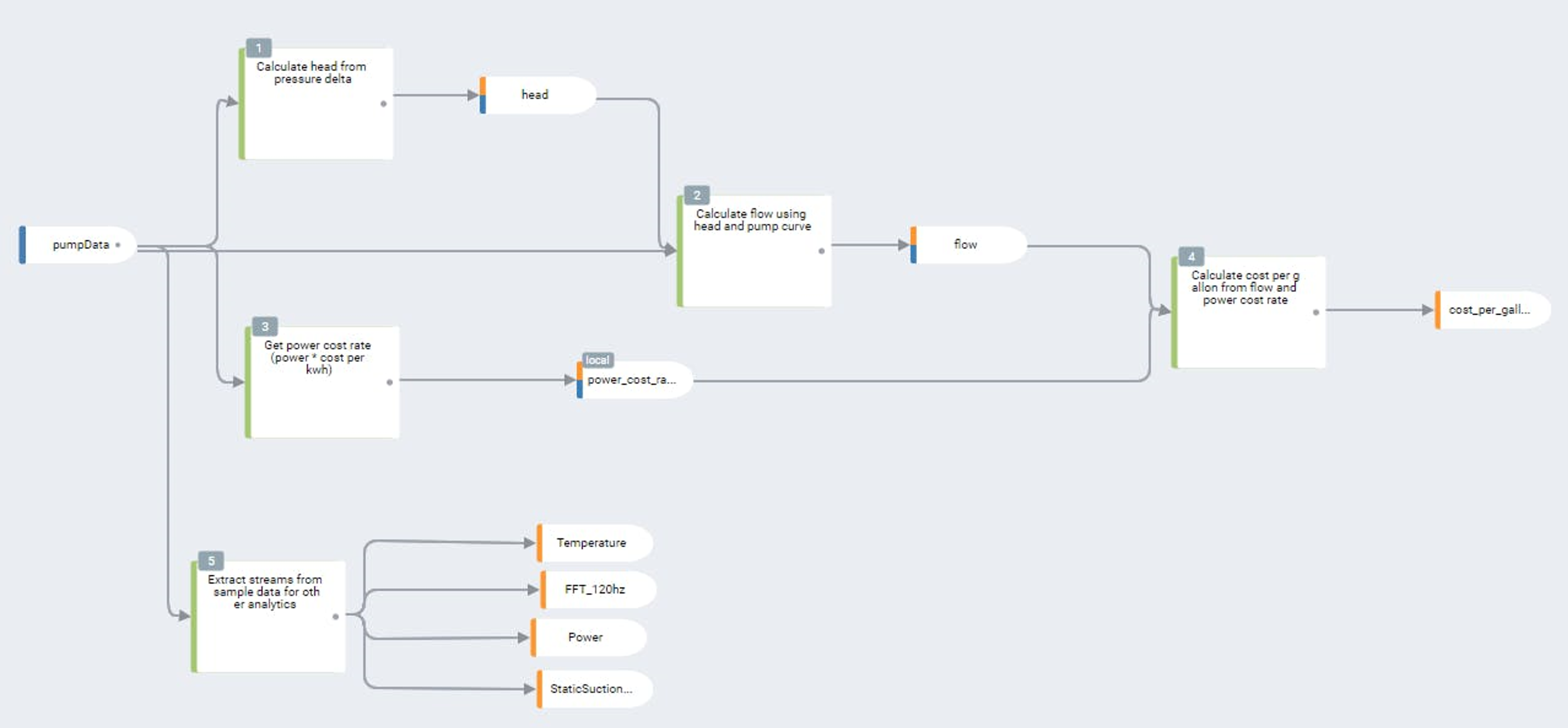
Une architecture conforme aux principes de l'Industrie 4.0 doit se concentrer sur trois types de données : Edge, Local et Remote. Le fait de concevoir pour un seul type de données expose les ingénieurs au risque de perdre des informations critiques sur les processus et des informations de grande valeur. En d'autres termes, en se concentrant uniquement sur les données de type Edge, Local ou Remote, on se retrouve toujours à opérer un choix, et comme le dit le proverbe : choisir, c'est renoncer.