Auteur: Karl D’haveloose
Cela faisait déjà un bout de temps que ce sujet figurait dans mon dossier 'idées pertinentes', et maintenant que les organisateurs de www.abissummit.be et www.abissummit.nl ont défini leur nouvelle mission stratégique ('Connecting every IT/OT dot in IioT'), je me suis dit que le moment était venu de coucher mes réflexions sur le papier.
Les arrêts de production, comme ceux survenus chez Jaguar Land Rover, sont inévitables, mais c'est la capacité à relancer la production en toute sécurité qui fait la résilience des fabricants innovants.
Lorsque Jaguar Land Rover a décidé de mettre ses systèmes hors ligne suite à un incident de sécurité, les gros titres des journaux se sont immédiatement concentrés sur les cyberrisques. Mais pour les fabricants qui suivaient la situation de près, la principale préoccupation n’était pas tant qu'un éventuel incident cybernétique puisse entraîner un arrêt de la production, mais plutôt le temps qu’il faudrait pour relancer la production.
À un moment donné, la construction automobile britannique a atteint son niveau le plus bas depuis 1952, provoquant une véritable onde de choc dans le secteur, dont tous les acteurs de la chaîne, depuis les fournisseurs jusqu'aux concessionnaires, ont subi les conséquences. Des questions ont été soulevées quant à un éventuel cyberincident et à sa nature, mais les incidents de ce type sont rarement dus à une seule vulnérabilité. Même lorsqu'un cyberincident entraîne l'arrêt de la production, l'incapacité à relancer rapidement les activités révèle souvent des problèmes bien plus profonds. Des décennies d'évolution technologique font que la reprise des activités est souvent lente, fragmentée et semée d'embûches liées au rétablissement des systèmes et à la compatibilité.
Des systèmes conçus pour une longue durée de vie, et non pour la continuité opérationnelle.

Il suffit de se promener dans n'importe quel atelier de fabrication pour constater la présence d'équipements, d'outils et de technologies opérationnelles datant d'il y a plusieurs décennies. Les systèmes d'exploitation sont conservés, car leur remplacement impliquerait de changer des machines certifiées. Les systèmes embarqués sont liés à des chipsets spécifiques. Les ordinateurs industriels dépendent de combinaisons précises de pilotes et de versions de micrologiciels qui ne peuvent pas être remplacées aussi facilement qu'on aimerait pouvoir le faire. Au fil du temps, ces environnements évoluent et de nouveaux composants viennent s'y ajouter, entraînant une accumulation de petits changements. Des mises à jour de micrologiciels sont appliquées, des composants de remplacement légèrement différents de leurs prédécesseurs sont installés, et des problèmes de configuration commencent petit à petit à apparaître.
Ainsi, lorsqu'une panne survient, ce qui finit toujours par arriver à un moment ou à un autre, le rétablissement ne se résume pas à 'simplement restaurer une sauvegarde'. Il faut en effet pouvoir revenir à un état opérationnel bien précis dans un environnement matériel qui n’est peut-être plus identique à celui qui était en place au moment où la sauvegarde avait été effectuée. Cela peut entraîner d’innombrables erreurs et problèmes d’incompatibilité qui ont pour effet de prolonger
Bien qu'un tableau de bord puisse indiquer qu'une sauvegarde a été effectuée avec succès, ces signaux numériques et drapeaux verts dans le domaine des technologies opérationnelles ne garantissent pas à eux seuls qu'un système restauré démarrera correctement à long terme. Rien qu'au Royaume-Uni, une récente étude menée par Censuswide a révélé que les fabricants perdent collectivement jusqu'à 736 millions de livres sterling par semaine en raison des temps d'arrêt. Et aux États-Unis, près de la moitié des fabricants signalent entre 6 et 10 incidents par semaine, pour un coût total estimé à plus de 207 millions de dollars. Rappelons en outre que le coût d’une panne ne se limite pas à l’incident lui-même, puisqu’il faut également prendre en compte le temps nécessaire pour rétablir la pleine capacité opérationnelle.
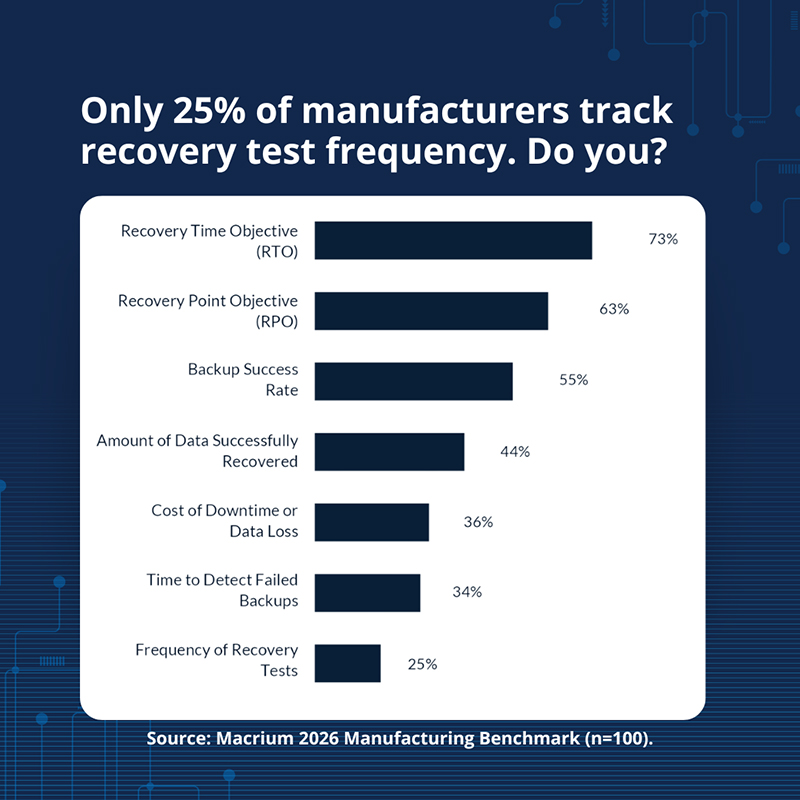
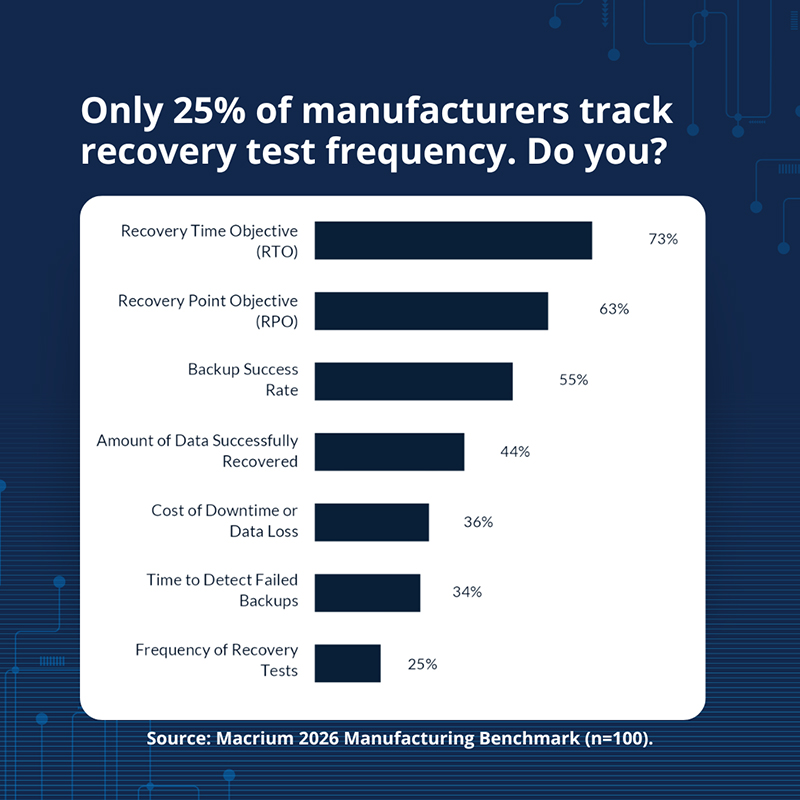
De nouvelles données révèlent un angle mort absolument critique : la plupart des fabricants enregistrent leurs valeurs RTO et RPO, mais seul 1 sur 4 vérifie à quelle fréquence il teste réellement le délai de rétablissement.
Lorsqu'il est question de rétablissement, 'mesurer' n'est pas synonyme de 'prouver'.
De nombreuses entreprises enregistrent, à très juste titre, leurs objectifs de délai de reprise (en anglais : Recovery Time Objective ou RTO) et leurs objectifs de point de reprise (en anglais : Recovery Point Objective ou RPO). Ces indicateurs sont importants, car ils fixent un objectif permettant de déterminer la rapidité avec laquelle les systèmes doivent pouvoir être restaurés et le niveau de perte de données jugé acceptable. Cependant, le simple fait d’enregistrer ces objectifs ne garantit pas que la restauration fonctionnera comme il se doit en cas de besoin. Selon le rapport comparatif de Macrium publié en 2026, 73 % des fabricants enregistrent leurs RTO et 63 % leurs RPO, mais seuls 25 % mesurent la fréquence à laquelle leurs capacités de rétablissement sont testées. Pour faire simple, cela signifie que beaucoup d'entreprises mesurent leur capacité de réaction plus souvent qu'elles ne la vérifient réellement. Dire que l'on est prêt et l'être réellement sont en effet deux choses totalement différentes.
Dans un environnement industriel, cet écart entre la capacité virtuelle et la capacité réelle peut être considérable. Une procédure de rétablissement qui fonctionne dans un environnement de test virtuel peut en effet toujours échouer lorsqu’elle est appliquée au matériel physique qui contrôle une ligne de production. Les différences au niveau des pilotes, des versions de micrologiciels ou des périphériques peuvent introduire des points de défaillance qui ne se révèlent qu’en situation réelle. La résilience repose ici sur la réduction des facteurs inconnus avant qu’un incident ne se produise, ce qui exige d’aller au-delà de l’hypothèse selon laquelle une sauvegarde effectuée avec succès équivaut à un système pouvant être rétabli.
D'une sauvegarde effectuée avec succès à la confiance dans le rétablissement.
En résumé, la réponse aux questions ci-dessus est que les dirigeants du secteur et les équipes IT/OT doivent se pencher sur la validation (et donc pas seulement sur la vérification) de leurs sauvegardes.
Les contrôles d'intégrité permettent de détecter à un stade précoce la corruption silencieuse des sauvegardes, tandis que les opérations de rétablissement planifiées confirment que les systèmes peuvent démarrer et que les opérations peuvent être lancées comme prévu. La validation périodique doit toujours être effectuée sur du matériel représentatif plutôt que sur de simples machines virtuelles, car les environnements de production sont rarement génériques et les plans de reprise d'activité doivent refléter cette réalité. Ce qui fonctionne dans un environnement ne fonctionne pas nécessairement dans un autre, même si les deux environnements appartiennent à la même entreprise et sont gérés par cette dernière.
La validation devient ici une pratique routinière plutôt qu’une simple liste de contrôle ou une question de conformité. Comme pour toute autre forme de diligence raisonnable, ces résultats doivent être documentés, les procédures optimisées et les simulations de scénarios de reprise des activités intégrées dans les opérations régulières, à mesure que l’environnement change et évolue au fil du temps. Le rétablissement devient ainsi prévisible plutôt qu’improvisé, et au lieu de se fier au simple 'feu vert' d’un tableau de bord, les équipes accumulent des preuves que le rétablissement fonctionnera bel et bien en situation de crise.
Le rétablissement doit devenir un automatisme opérationnel
Pendant des années, les discussions sur la résilience dans l’industrie manufacturière se sont concentrées sur la prévention, la segmentation des réseaux, la détection des menaces et le raccourcissement des délais de réaction jouant ici un rôle essentiel. Mais dans les réseaux interconnectés utilisés à l’ère de l’Industrie 4.0, aucune stratégie de défense ne peut être infaillible. Il y aura toujours des incidents qui se produiront et des perturbations qui s’ensuivront. Les entreprises qui parviennent à se remettre efficacement de ces incidents avec un minimum de pertes ont toutes un point commun : elles s'entraînent, simulent, mesurent et documentent. La différence entre une interruption temporaire et un arrêt prolongé réside souvent dans la préparation qui a eu lieu plusieurs mois plus tôt. Les incidents sont peut-être inévitables, mais les périodes d'indisponibilité prolongée qui coûtent des fortunes ne le sont pas.